AWS Lambda explained: The event-driven engine behind serverless
What AWS Lambda is, how the event-driven execution model works, and where it fits in a serverless architecture.

One comment on a Reddit thread sums up the trade-off well: "Yes, it's more expensive, but here's how I look at it, you are paying a small price to have one of the best IT orgs in the business to manage, scale, and patch your compute power for you. You write code, they take care of the rest."
When AWS Lambda launched in 2014, it introduced a lot of developers to the term "serverless computing." That term has caused some confusion about how Lambda actually runs.
You don't manage servers with Lambda, true. But knowing what happens behind the scenes helps you tune your functions and make better architectural calls.
What this guide covers
How AWS Lambda works under the hood: the event-based model behind the "serverless" label, and enough of the mechanics to build Lambda applications that hold up.
What AWS Lambda actually is
AWS Lambda runs on a simple model. It's your code, executing in response to events.
The point was never to get rid of servers. They're still there. The point was to hide all the infrastructure management so you can spend your time on business logic instead. That abstraction is why Lambda is useful, and also why it trips up developers when they first meet it.
Lambda has two core parts:
- Your code A function written in a supported language (Python, Node.js, Java, etc.)
- Event-driven execution: A mechanism that triggers your code in response to events
AWS handles the rest: the infrastructure, the scaling, the management.
How AWS Lambda works: the event-driven model
The thing to get straight about Lambda is that it's event-driven. Whatever the trigger, a Lambda function always:
- Receive a JSON event
- Process that event
- Return a response (for synchronous invocations)
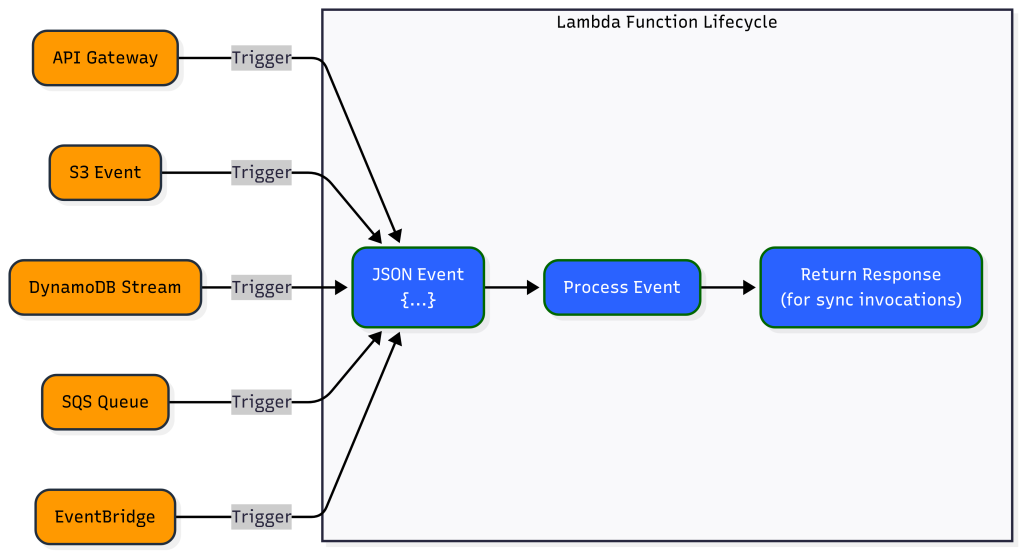
Here are three common event sources and how Lambda handles each.
1. API Gateway to Lambda
API Gateway creates RESTful HTTP endpoints that trigger Lambda functions when clients make requests. This is the usual way to build serverless APIs and web applications.
Use cases: Web APIs, mobile backends, webhook receivers, and anything that needs HTTP endpoints to run code.

{
"resource": "/users",
"path": "/users",
"httpMethod": "POST",
"headers": {
"Content-Type": "application/json"
},
"body": "{\"name\":\"John Doe\",\"email\":\"john@example.com\"}",
"isBase64Encoded": false
}
Sample API Gateway Event
import json
def lambda_handler(event, context):
# Parse the incoming JSON body
request_body = json.loads(event['body'])
# Extract user information
name = request_body.get('name')
email = request_body.get('email')
# Process the data (e.g., store in database)
# ...
# Return a response
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json'
},
'body': json.dumps({
'message': f'User {name} created successfully'
})
}
Python Lambda Handler
2. S3 to Lambda
S3 can trigger Lambda functions when specific events happen in a bucket: file uploads, deletions, or metadata changes. Your function receives details about the S3 event and can act on the affected objects.
Use cases: Image and video processing, file validation, data extraction, format conversion, and workflows that kick off when a file lands.

{
"Records": [
{
"eventSource": "aws:s3",
"eventName": "ObjectCreated:Put",
"s3": {
"bucket": {
"name": "my-uploads-bucket"
},
"object": {
"key": "uploads/document.pdf",
"size": 1048576
}
}
}
]
}
Sample S3 Event
import boto3
def lambda_handler(event, context):
# Extract bucket and key information
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# Initialize S3 client
s3 = boto3.client('s3')
# Process the file (e.g., extract text, resize image)
# ...
# Return processing result
return {
'status': 'success',
'processed': {
'bucket': bucket,
'key': key
}
}
Python Lambda Handler
3. SQS to Lambda
Amazon Simple Queue Service (SQS) is a managed message queuing service. Set up as a Lambda trigger, SQS invokes your function with batches of messages from the queue, so the work happens asynchronously.
Use cases: Task processing, distributed systems, workload buffering, event handling, and anything where you need to decouple components and process tasks asynchronously.

{
"Records": [
{
"messageId": "059f36b4-87a3-44ab-83d2-661975830a7d",
"body": "{\"orderId\":\"12345\",\"product\":\"Widget\",\"quantity\":2}",
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-1:123456789012:my-queue"
},
{
"messageId": "2e1424d4-f796-459a-8184-9c92662be6da",
"body": "{\"orderId\":\"67890\",\"product\":\"Gadget\",\"quantity\":1}",
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-1:123456789012:my-queue"
}
]
}
Sample SQS Event
import json
def lambda_handler(event, context):
# Process each message in the batch
for record in event['Records']:
# Parse the message body
message = json.loads(record['body'])
# Extract order information
order_id = message.get('orderId')
product = message.get('product')
quantity = message.get('quantity')
# Process the order (e.g., update inventory, notify shipping)
print(f"Processing order {order_id}: {quantity} x {product}")
# ...
# Return successful processing (empty list means all messages succeeded)
return {
'batchItemFailures': []
}
Python Lambda Handler
Behind the scenes: what's actually running your code
You don't need any of this to use Lambda well, but here's what happens behind the curtain:
✓ Lambda runs your code in an isolated environment built for security and performance.
✓ On invocation, your code is loaded, the runtime initializes, and your function executes.
✓ After execution, the environment can stay "warm" for the next invocation or get torn down.
The Lambda execution lifecycle
A typical Lambda invocation runs through this sequence:
- Event Occurs Something happens (HTTP request, file upload, message arrival)
- Lambda Service Receives Event AWS routes the JSON event to your function
- Environment Provisioning If no warm environment exists, AWS provisions one
- Function Execution Your code processes the event
- Response Your function returns a response (for synchronous invocations)
- Environment Status The environment stays warm for a period, ready for more invocations
Practical implications for developers
The event-driven model has a few consequences worth designing around:
- **Build around JSON **Structure your code to parse and emit JSON without friction.
- **Keep Functions Focused **Each function should answer to specific events for a specific purpose.
- **Use Warm Starts **Code outside your handler function runs only during cold starts.
- **Be Stateless **Never assume your function's memory will survive between invocations.
- **Monitor Execution Time **You pay for the time your code runs, so efficiency matters.
Conclusion
Lambda isn't magic. It's your code responding to events in a managed environment.
What makes it worth using is the abstraction: the infrastructure stays out of your way, and you write business logic. Once you see Lambda as an event processor that consumes JSON and runs your code in response, the cost-efficient, auto-scaling part starts to make sense.
Need help designing the right Lambda architecture for your project? At safeINIT, we build scalable, secure, cost-efficient serverless applications on AWS, from event-driven workflows to API backends, shaped to what your business actually needs. Learn more about us here.
Frequently asked questions
Is AWS Lambda really serverless if servers still exist behind the scenes?
Yes. Lambda counts as serverless because AWS takes over the server management. Servers still run Lambda underneath, but you don't provision, scale, or patch them. AWS does that part.
Why does Lambda always process a JSON event?
Events trigger Lambda functions, and AWS standardizes those triggers as JSON payloads. An API call, an S3 upload, an SQS message: each one arrives as a JSON event that your function parses and processes.
What is a "warm start" in AWS Lambda?
A warm start is when Lambda reuses an execution environment from a previous invocation instead of building a new one, which cuts startup latency. It matters for performance and cost, since a cold start can add milliseconds or even seconds of delay.
Can Lambda only be used with HTTP APIs?
No. Lambda is event-driven and supports many triggers beyond HTTP APIs: S3 event notifications, DynamoDB streams, SQS queues, EventBridge events. It works well for serverless APIs, but also for background jobs, file processing, and real-time data pipelines.
Do I pay for Lambda when it's idle?
No. Lambda is pay-per-invocation. You're charged only when your code runs, based on compute time and memory allocation. An idle function costs nothing.